|
|
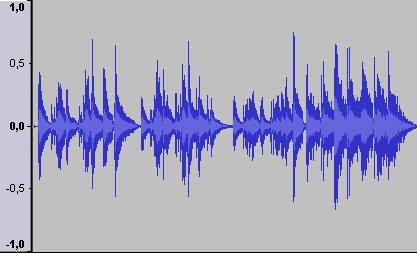
Na czym polega kompresja plików audio?Standardowy zapis cyfrowego dźwiękuZapis dźwięku w formacie cyfrowym polega na zapisaniu kształtu sygnału w postaci ciągu liczb. Procedura powyższa nazywana jest próbkowaniem (więcej na temat próbkowania znajduje się w osobnym rozdziale). Kolejne naniesienia tych liczb na wykres pozwalają na graficzne przestawienie przebiegu sygnału.
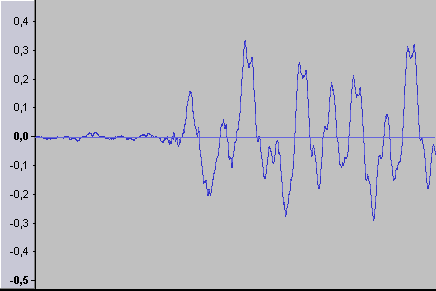
W powiększeniu widać wyraźnie poszczególne wartości sygnału muzycznego:
Przy kodowaniu 16 bitowym (jak na płycie CD) wysokość "pików" na wykresie musi mieścić się granicach od 0 do 215 - czyli od 0 do ±32 768 (z 16 bitów jeden jest zarezerwowany na zapisanie znaku sygnału - czyli czy jest on nad, czy pod osią). Wartość sygnału jest zapisywana z pewną częstotliwością zwaną "częstotliwością próbkowania". W przypadku płyty CD częstotliwość ta wynosi 44,1 kHz, co oznacza, że w ciągu sekundy zapisywane jest 44 100 wartości sygnału audio. Mnożąc 16 bitów przez 44100 otrzymujemy konieczność zapisania nieco ponad 700 000 bitów na sekundę, czyli 88 200 bajtów na sekundę (1 bajt = 8 bitów). Ponieważ zazwyczaj zapis odbywa się dwukanałowo (stereo), to powyższą liczbę należy pomnożyć jeszcze przez 2, co da ostatecznie ok. 1 400 000 bitów na sekundę i 176 400 bajtów na sekundę - w przybliżeniu ok. 170 kB/s. Łatwo stąd obliczyć, że jedna minuta muzyki wymaga
przestrzeni dyskowej na poziomie 170 kb/s x 60 s, czyli ok. 10 000 kB - w przybliżeniu 10
MB. Standardowymi formatami plików dźwiękowych są (bez użycia kompresji):
W bardzo podobny sposób zapisywane są dane dźwiękowe na płytach CD, DVD (część podformatów), DVD Audio (część podformatów). tylko audiofilski format SACD opracowany przez SONY zapisuje dane w nieco innych sposób niż opisany powyżej. KompresjaZ pomocą potrzebom przesyłania muzyki przez Internet przychodzi kompresja, czyli "pakowanie" danych dźwiękowych. Są dwa rodzaje kompresji:
Kompresja bezstratnaKompresja bezstratna zachowuje pełną informację o przebiegu sygnału dźwiękowego. Polega ona na sprytnej zmianie sposobu zapisu danych, dzięki czemu zapis jest oszczędniejszy. Możliwość stosowania tego rodzaju kompresji wynika z faktu, że standardowe sposoby zapisu dźwięku (np. pliki wav) są dość "rozrzutne" pod względem wykorzystania pamięci. Np. bez względu na to, czy w danym momencie dźwięk ma dużą amplitudę i skomplikowany przebieg, czy panuje absolutna cisza, dane w formacie stereo zajmują około 170 kB na każdą sekundę. Dlatego zmieniając sposób zapisu da się sporo danych "upakować". Zwykle kompresja bezstratna pozwala przeciętnie w np. w jednym bajcie danych skompresowanych zapisać więcej niż 1 bajt danych wyjściowych. Możliwe do zastosowanie metody to m.in. dlatego że:
- można np. oznaczać obszary ciszy i zapisywać je oszczędniej
niż w 16 bitach na kanał i na jedną próbkę sygnału (w końcu większość rozpiętości przedziału od 0 do
32 768 dla cichych dźwięków się "marnuje") Formaty kompresji bezstratnej są różne. Przykładem może być tu np.
Niestety, kompresja bezstratna zazwyczaj nie daje dużych możliwości zmniejszenia rozmiaru plików - zysk na pojemności pamięci oscyluje w okolicy 2 razy (w najlepszych warunkach 3-4). Dlatego stosuje się nieco gorszą jeśli chodzi o wierność zapisu, ale znacznie wydajniejszą - kompresję stratną.
Kompresja stratnaKompresja stratna wykorzystuje kilka uzupełniających się efektów i technik:
Ta druga metoda - wykorzystanie niedokładności słuchu jest właśnie kluczem do wydajności kompresji stratnej. W jej ramach sygnał dźwiękowy jest analizowany pod kątem owych niedostrzeganych słuchem elementów - np. maskowanie dźwięków cichych przez głośne, lub maskowanie gorzej słyszalnych dźwięków (patrz wykres czułości słuchu). Dzięki kompresji stratnej daje się (bez wyraźnego pogorszenia jakości dźwięku) upakować dane audio 10-cio, a nawet 20-to krotnie. W rezultacie typowe nagranie zajmuje nie kilkadziesiąt, a kilka megabajtów pamięci. Kompresję stratną stosuje się w następujących formatach zapisu dźwięku:
Dodatkowe informacje na ten temat znajduje się w tabeli właściwości typowych formatów audio. |